New Evaluation Metrics for Mesh Segmentation
 |
Decomposing 3D models into meaningful parts has been an increasing topic in the shape analysis community. The tasks such as skeleton extraction, shape partial matching, shape correspondence, texture mapping, shape deformation, and shape annotation heavily rely on 3D model segmentation. Many methods have attempted to provide better segmentation solutions, however, determining which method is superior to other methods is not an easy task. Similar as many shape retrieval benchmarks proposed previously, Benhabiles et |
al. first provide a pioneering framework to quantitatively evaluate segmentation algorithms. Chen et al. also propose a benchmark, which comprises a dataset with 4300 manually generated segmentations for 380 surface meshes of 19 different object categories. In addition, it offers four quantitative metrics for comparison of segmentations. The four metrics are obtained by extending metrics from image segmentation, and researchers adopt part or all of metrics to test their methods. Although these metrics are widely accepted by researchers, one-to-one comparison between automatic and ground-truth segmentation, and the way of averaging on all the comparisons limits their performance. Moreover, they are unable to be directly applied to multiple standard comparison.
(source code)
Human-Centered Saliency Detection
 |
We introduce a new concept for detecting the saliency of 3-D shapes, that is, human-centered saliency (HCS) detection on the surface of shapes, whereby a given shape is analyzed not based on geometric or topological features directly obtained from the shape itself, but by studying how a human uses the object. Using virtual agents to simulate the ways in which humans interact with objects helps to understand shapes and detect their salient parts in relation to their functions. HCS |
detection is less affected by inconsistencies between the geometry or topology of the analyzed 3-D shapes. The potential benefit of the proposed method is that it is adaptable to variable shapes with the same semantics, as well as being robust against a geometrical and topological noise. Given a 3-D shape, its salient part is detected by automatically selecting a corresponding agent and making them interact with each other. Their adaption and alignment depend on an optimization framework and a training process. We demonstrate the detected salient parts for different types of objects together with the stability thereof. The salient parts can be used for important vision tasks, such as 3-D shape retrieval.
(paper)(dataset:HumanCentered,SHREC-PART1,SHREC-PART2)
Template Deformation Based 3D Reconstruction of Full Human BodyScans from Low-Cost Depth Cameras
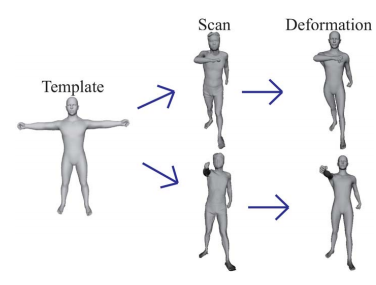
|
Full human body shape scans provide valuable data for a variety of applications including anthropometric surveying, clothing design, human-factors engineering, health, and entertainment. However, the high price, large volume, and difficulty of operating professional 3-D scanners preclude their use in home entertainment. Recently, portable low-cost red green blue-depth cameras such as the Kinect have become popular for computer vision tasks. However, the infrared mechanism of this type of camera leads to noisy and incomplete depth images. We construct a stereo full-body scanning environment composed of multiple depth cameras and propose a novel registration algorithm. Our algorithm determines a segment constrained correspondence for two neighboring views, integrating them using rigid transformation. Furthermore, it aligns all of the views based on uniform error distribution. The generated 3-D mesh model is typically sparse, noisy, and even with holes, which makes it lose surface details. To address this, we introduce a geometric and topological fitting prior in the form of a professionally designed high-resolution template model. We formulate a template deformation optimization problem to fit the high-resolution model to the low-quality scan. Its solution overcomes the obstacles posed by different poses, varying body details, and surface noise. The entire process is free of body and template markers, fully automatic, and achieves satisfactory reconstruction results. YouTube video
Youku video
|
Learning High-level Feature by Deep Belief Networks for 3D Model Retrieval and Recognition
 |
In this paper, we propose a multi-level 3D shape feature extraction framework by using deep learning. To the best of our knowledge, it is the first time to apply deep learning into 3D shape analysis. Experiments on 3D shape recognition and retrieval demonstrate the superior performance of the proposed method in comparison to the state-of-the-art methods. We implement a deep learning toolbox with GPU which can boost the computation performance greatly. The source code is publicly available and easy to use. |
NPU RGB-D Dataset
 |
In order to evaluate the RGB-D SLAM algorithms of handling large-scale sequences, we recorded this dataset which contains several sequences in the campus of Northwestern Polytechnical University with a Kinect for XBOX 360. This is a challenging dataset since it contains fast motion, rolling shutter, repetitive scenes, and even poor depth informations. (dataset) |